Note (2026) : Amazon Sumerian a été arrêté par AWS en février 2023, ce tutoriel n’est donc plus réalisable en l’état. Il est conservé ici à titre historique.
Dans ce tutoriel, nous allons voir comment créer un hôte virtuel sur AWS Sumerian, capable de discuter et de reconnaitre votre visage et vos émotions.
Introduction

Fonctionnalités
Le but de ce tutoriel est de créer une scène avec un hôte capable d’écouter et de comprendre ce que vous lui dites en appuyant sur la barre espace ou sur un bouton.
L’hôte pourra activer sur demande la webcam, afin de détecter vos émotions et de reconnaître votre visage.
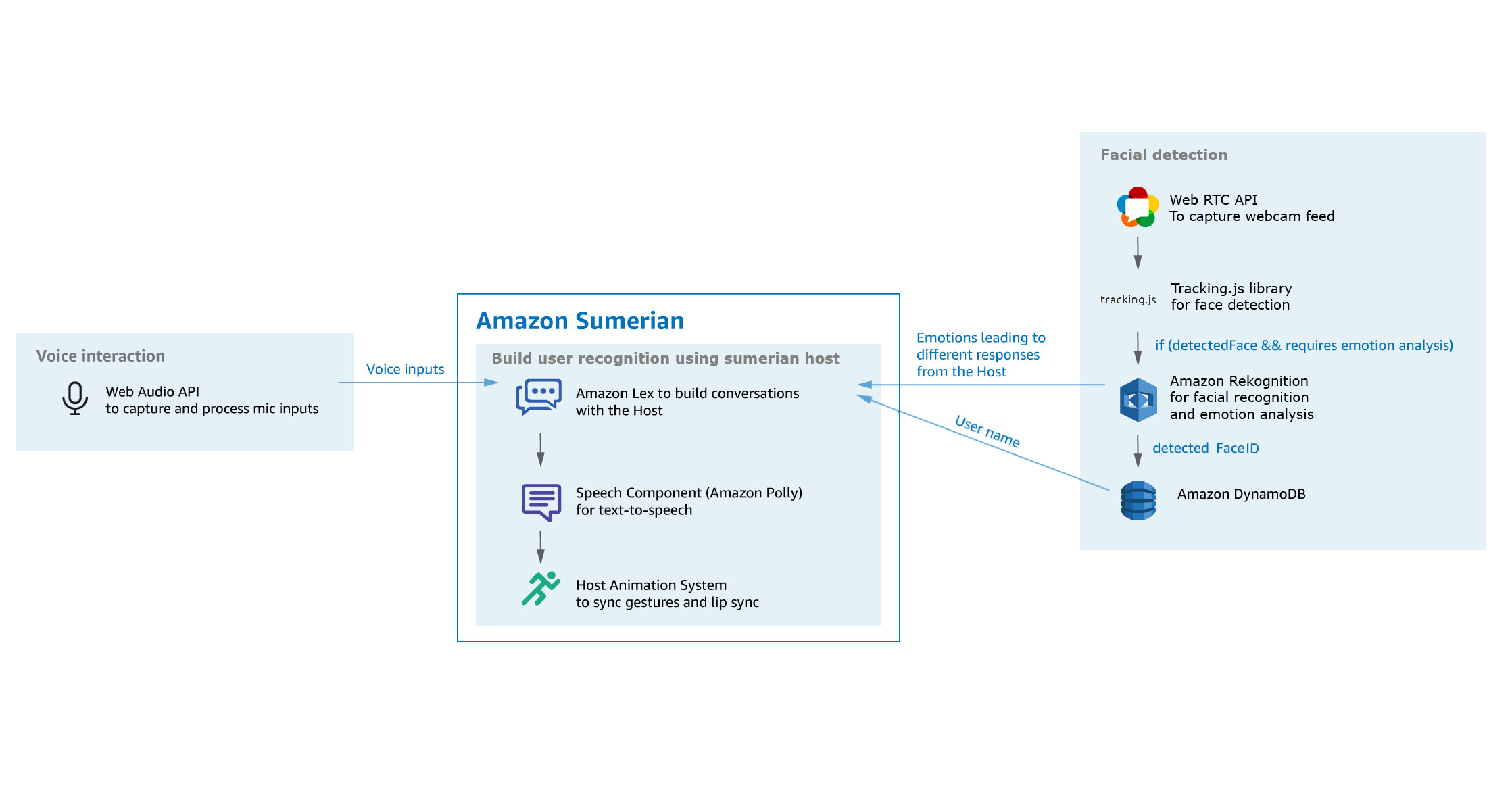
Tout ce projet sera réalisé sur AWS Sumerian, à l’aide des technologies AWS et du SDK AWS pour JavaScript
Prérequis
- Webcam, microphone et haut-parleurs
- Connectez-vous à Sumerian à l’aide de votre compte AWS
- Téléchargez les ressources de base du projet
- Téléchargez les scripts à utiliser
- Maîtrisez les bases de l’utilisation de Sumerian
- Soyez à l’aise avec les scripts et les machines à états sur Sumerian.
Technologies
- Amazon Sumerian : Utilisé pour créer la scène, gérer les interactions avec l’utilisateur et afficher un hôte virtuel avec lequel vous pouvez interagir comme un chatbot.
- Amazon Lex : Service de création de chatbot vocal et textuel. Ce service sera utilisé pour interagir avec l’hôte à l’aide de votre microphone afin de discuter avec et lui donner des instructions.
- Amazon Rekognition : Service de reconnaissance d’images et de vidéos permettant la reconnaissance faciale, l’analyse des émotions.
- Amazon DynamoDB : Base de données AWS qui sera utilisée pour enregistrer l’ID de la face et les noms d’utilisateur.
- Tracking.js : Bibliothèque JavaScript basée sur OpenCV pour détecter les visages sur les vidéos et les images.
Configuration de la scène
Gestion des droits d’accès
Tout d’abord, vous devrez créer et configurer une nouvelle scène sur Sumerian en lui accordant tous les accès AWS dont vous avez besoin. Pour cela, créez un Cognito Identity Pool en suivant ce tutoriel. Ce Cognito Identity Pool va fournir aux utilisateurs Sumerian un token temporaire vous permettant d’utiliser les services AWS depuis Sumerian tels que Lex, Rekognition …
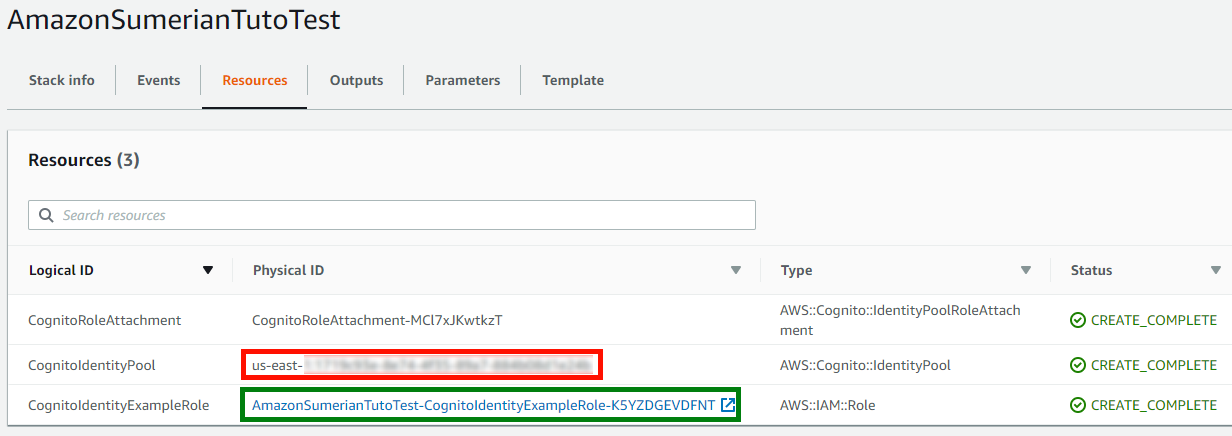
Une fois le Cognito Identity Pool créé en sélectionnant les modèles Polly et Lex, vous pouvez obtenir son ID (zone rouge) et configurer votre scène Sumerian à l’aide de celui-ci.
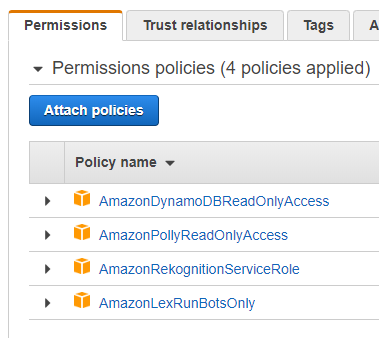
Par défaut, vous ne pourrez accéder qu’à Lex et à Polly. Pour ajouter les droits d’accès à Rekognition et DynamoDB, cliquez sur le lien du rôle (zone verte), puis ajoutez-lui des droits, comme indiqué ci-dessous.
Importation des fichiers et ressources par défaut
Pour importer les ressources défaut sur Sumerian, suivez la section Re-Importing an Exported Sumerian Bundle de ce tutoriel en important les ressources par défaut.
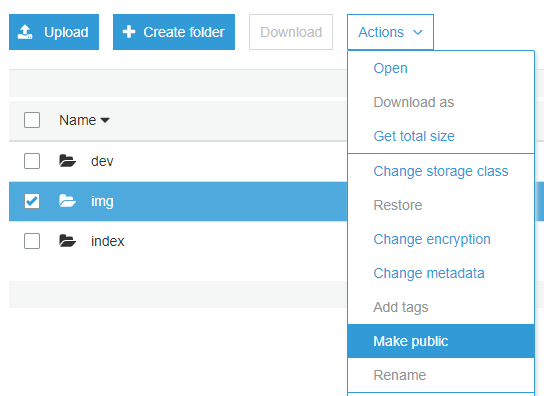
Cette scène a également besoin de quelques fichiers pour fonctionner. Pour ce faire, allez sur S3, créez un nouveau bucket et importez le dossier scripts. Assurez-vous de rendre le dossier public pour permettre à Sumerian d’y accéder.
Par défaut, la scène contient les éléments suivants :
- WebcamButton et MicroButton : Entités 3D représentant les deux boutons
- Webcam : Entité 3DHTML représentant l’affichage de la caméra et l’affichage du résultat de la reconnaissance.
- Cristine : L’hôte Sumerian
Ainsi que les scripts suivants :
- MicrophoneScript : Initialise tous les évènements liés au microphone.
- RecognitionScript : Fonctions de reconnaissance.
- SwitchOnWebcamScript/SwitchOffWebcamScript : Fonction permettant l’activation et la désactivation du flux vidéo.
- WebcamScript : Initialise l’évènement d’activation de la webcam.
Maintenant que les bases de la scène sont configurées, nous allons commencer par implémenter l’interaction vocale avec l’hôte à l’aide de Lex.
Chatbot avec Lex
Création du chatbot
Dans notre cas, le chatbot Lex sera principalement utilisé pour demander à l’hôte d’activer et de désactiver la webcam afin de démarrer la reconnaissance faciale.
Commençons par créer le chatbot en vous rendant sur votre console Lex et suivez les instructions suivantes :
- Dans la section Bots, cliquez sur le bouton Create
- Sélectionnez un bot Custom sur la page Create your bot
- Personnalisez votre bot avec un nom, une voix adéquate avec l’aspect de votre hôte … Comme ci-dessous
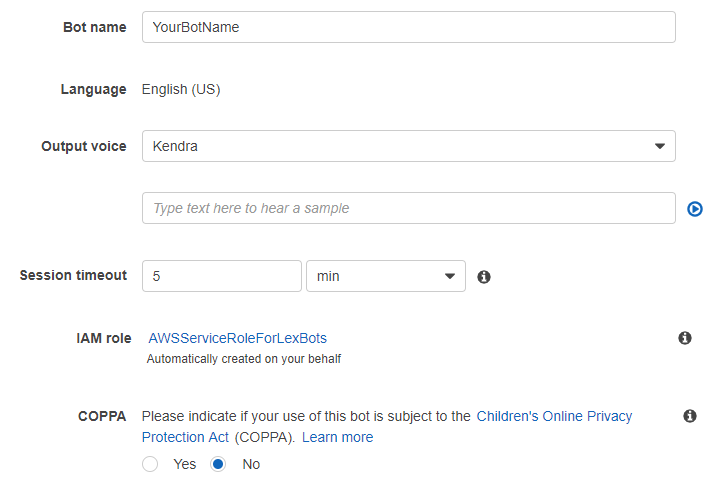
L’étape suivante consiste à créer un Intent (action personnalisable reconnue par le chatbot). Cliquez simplement sur le bouton Create Intent et nommez-le (par exemple, ChangeCameraStatus dans notre cas).
Nous voulons maintenant connaître dans quel état l’utilisateur souhaite mettre sa webcam (allumée ou éteinte). Cet état de la webcam peut être géré par un Slot. Cliquez sur le bouton + à côté de Slot types et configurez le slot en lui attribuant un nom et deux valeurs : On et Off. Cliquez ensuite sur le bouton Add slot to Intent.
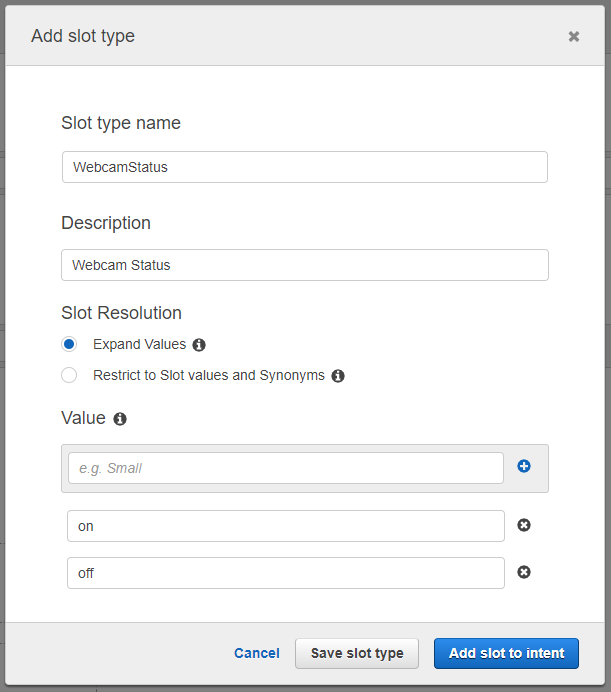
Il ne reste plus qu’à configurer le chatbot en ajoutant des fonctionnalités à l’Intent :
- Ajoutez le slot à l’Intent, attribuez lui un nom …
- Ajouter des expressions reconnues par le chatbot en utilisant le nom du slot comme paramètre dans les expressions
- Ajouter des réponses à utiliser lorsque le bot reçoit la demande de l’utilisateur
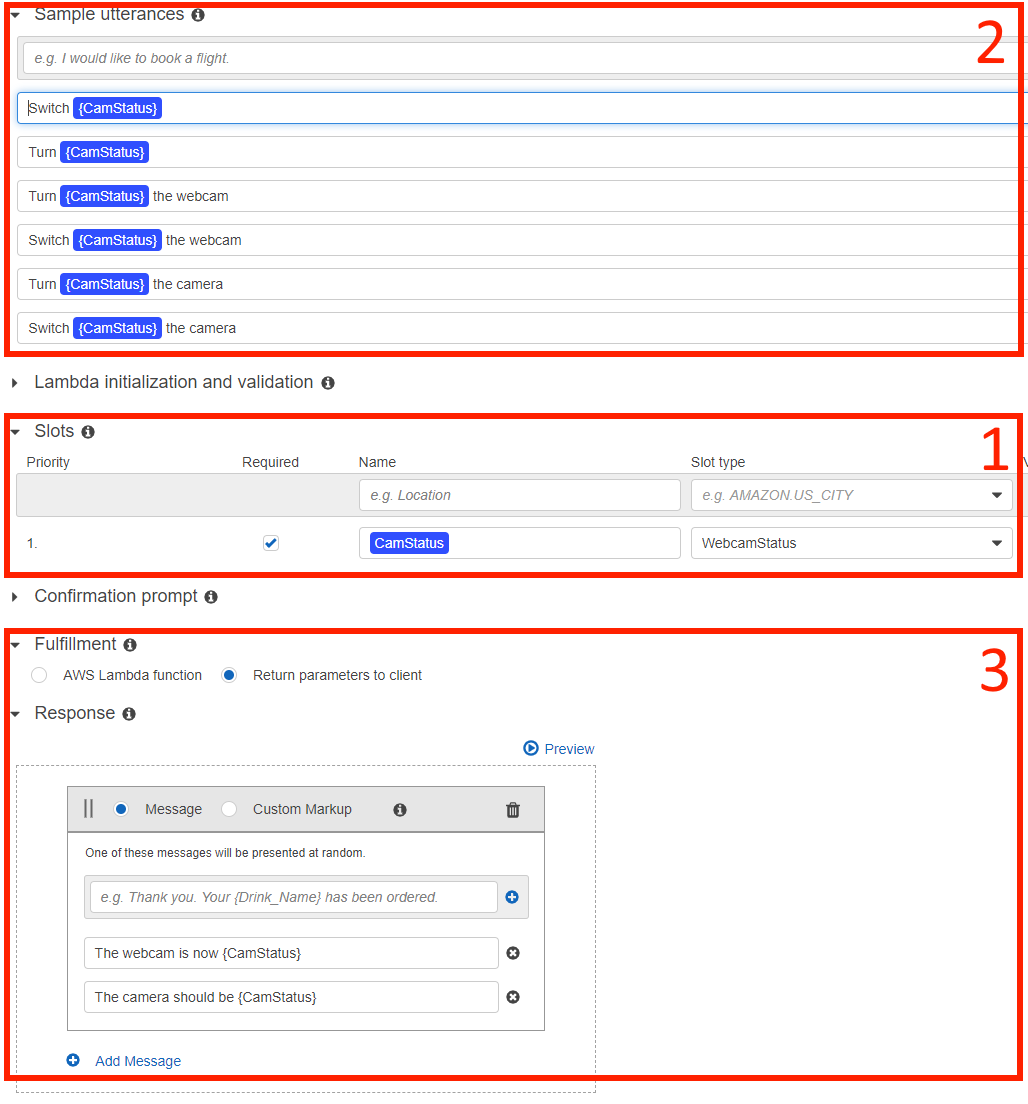
Enfin, cliquez sur le bouton Build en haut de la page et attendez que le chatbot soit prêt.
Configuration de l’hôte sur Sumerian
Le chatbot Lex maintenant créé, nous allons configurer l’hôte sur Sumerian afin qu’il utilise ce chatbot pour réagir aux interactions vocales avec l’utilisateur.
Commencez par assigner un composant de dialogue à l’hôte. Vous devez simplement sélectionner votre entité hôte dans le panneau Sumerian Entities, ajouter un composant Dialogue, configurez-le avec le nom de votre chatbot (comme défini précédemment) et définir $LATEST comme version.
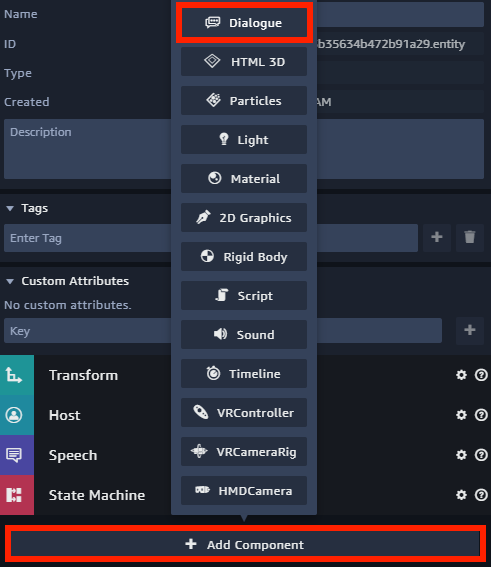
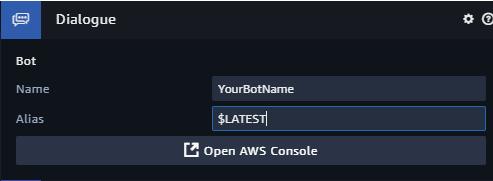
Une fois le composant de dialogue ajouté, ajoutez le Behaviour ci-dessous à l’hôte.
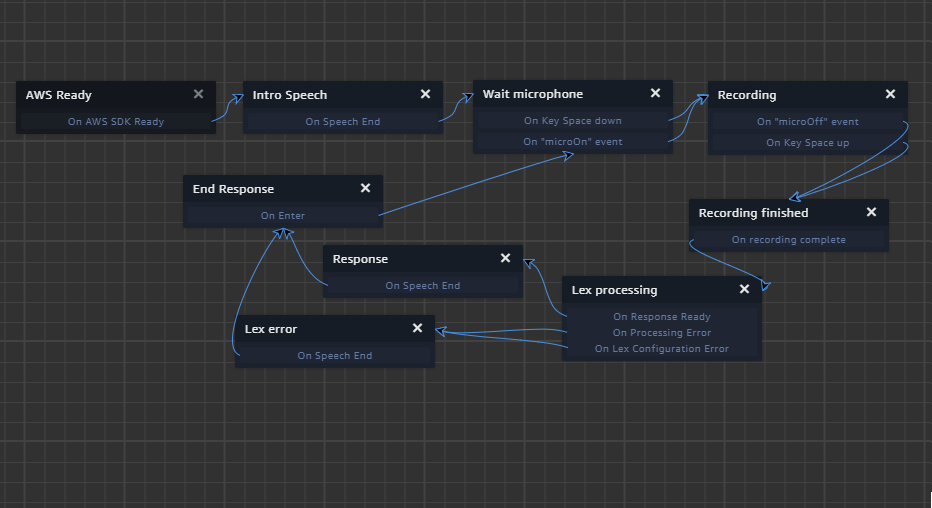
Ce Behaviour fonctionne comme ceci :
- AWS Ready : Attend que le SDK AWS soit chargé
- Intro Speech : Lit un discours d’introduction pour présenter l’hôte
- Wait Microphone : Attend que la touche Espace soit enfoncée ou que le message microOn soit émis (lorsque vous appuyez sur le bouton du microphone).
- Recording : Contient une action start Microphone Recording pour effectuer un enregistrement, émet le message startRecord (utilisé pour modifier l’aspect du bouton du microphone) et attend la fin de l’enregistrement lorsque la touche Espace ou le message microOff soit émis (lorsque le bouton du microphone est relâché).
- Recording finished : Emet le message endRecord et contient une action stop Microphone Recording.
- Lex Processing : Envoie le message enregistré à Lex.
- Response & Lex error : Lit la réponse vocale de Lex.
- End Response : Emet le endMessage pour réinitialiser l’aspect du bouton du microphone.
Enfin, pour intercepter tous les messages émis par ce Behaviour, ainsi que pour ajouter des événements sur le bouton du microphone, ajoutez un composant de Script à l’entité MicroButton, faites glisser le script MicrophoneScript vers ce composant et indiquez au script les deux paramètres requis. Ces paramètres sont le nom de l’Intent et du Slot pour activer la webcam.
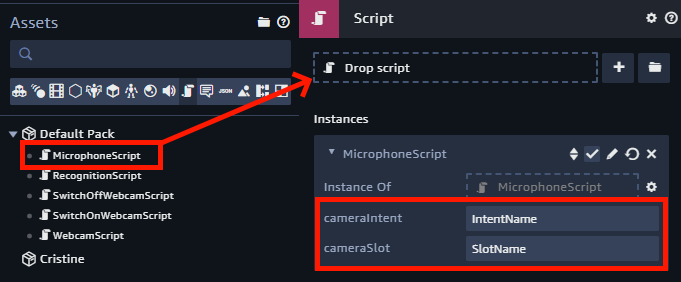
Webcam
Pour le moment, vous pouvez demander à l’hôte d’allumer et d’éteindre la webcam. Le chatbot Lex vous répondra que l’état de la webcam a été modifié, mais rien ne se passe vraiment.
Pour gérer la réponse de Lex et la convertir en action permettant de modifier l’état de la caméra, vous devez ajouter le code suivant à la fonction initLexResponseEvent du fichier MicrophoneScript.
ctx.onLexResponse = (data) => {
if (data.dialogState === "Fulfilled") {
if(data.intentName === args.intentCam){
switch (data.slots[args.slotCam]){
case "on":
sumerian.SystemBus.emit("switchOn");
break;
case "off":
sumerian.SystemBus.emit("switchOff");
break;
default:
break;
}
}
}
}
sumerian.SystemBus.addListener( `${sumerian.SystemBusMessage.LEX_RESPONSE}.${ctx.entity.id}`, ctx.onLexResponse);
Après cela, la fonction onLexResponse doit détecter le moment où l’utilisateur appelle l’Intent de Lex de modifier l’état de la webcam et émet le message correct (switchOn ou switchOff).
Ensuite, afin que le bouton de caméra puisse lui aussi émettre les messages switchOn et switchOff quand il est appuyé ou relâché, il suffit de créer un composant Script à l’entité WebcamButton et de lui ajouter le script WebcamScript.
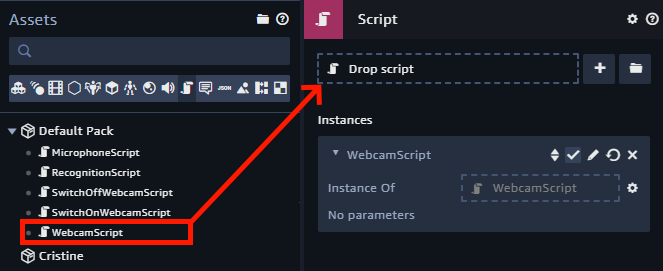
Ce script définit une variable globale cameraOn afin de sauvegarder l’état de la caméra dans tout le programme (allumée ou éteinte) et émet le message switchOn ou switchOff en fonction de l’état de la caméra quand le bouton est pressé.
if(Boolean(ctx.worldData.cameraOn)){
sumerian.SystemBus.emit("switchOff");
}else{
sumerian.SystemBus.emit("switchOn");
}
Enfin, ces deux messages doivent être reçus par un nouveau Behaviour. Attachez-le à l’entité Webcam et modifiez-le comme ci-dessous.
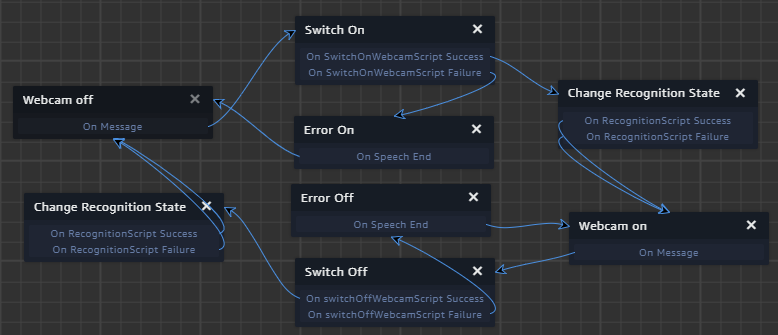
- Webcam off/on : Attend respectivement l’émission du message switchOn et switchOff.
- Switch on/off : Exécute respectivement les scripts SwitchOnWebcamScript et SwitchOffWebcamScript.
- Change Recognition State : Exécute le script RecognitionScript (que nous allons configurer plus tard).
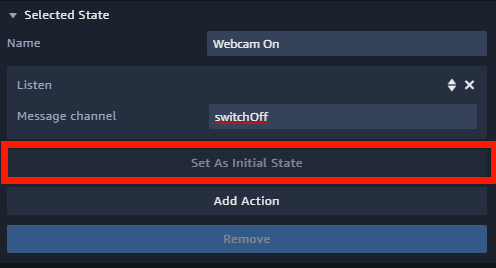
Faites attention à bien définir l’état Webcam On comme l’état initial en cliquant sur l’état puis sur Set As Initial State.
Les scripts activant la webcam utilisent l’API WebRTC pour diffuser le flux de la webcam sur l’entité 3DHTML appelée Webcam. Une fois la webcam activée, la variable de contexte ctx.worldData.cameraOn passe à true pour sauvegarder l’état actuel de la caméra au sein de tout le programme. Pour fonctionner, copiez le code ci-dessous dans la fonction switchOnWebcam dans le script SwitchOnWebcamScript.
function switchOnWebcam(ctx){
const video = document.getElementById("video");
navigator.getMedia = (navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia ||
navigator.msGetUserMedia);
navigator.getMedia({
video: true,
audio: false
}, function(stream) {
let vendorURL = window.URL || window.webkitURL;
video.srcObject=stream;
video.play();
}, function(error) {
console.log(error);
});
ctx.worldData.cameraOn = true;
}
À l’inverse, lorsque la caméra est désactivée, la variable de contexte ctx.worldData.cameraOn passe à false et la diffusion du flux vidéo est arrêtée. Pour fonctionner, copiez le code ci-dessous dans la fonction switchOffWebcam dans le script SwitchOffWebcamScript.
function switchOffWebcam(ctx){
const video = document.getElementById('video');
video.pause();
video.src="";
video.srcObject=null;
video.load();
ctx.worldData.cameraOn = false;
}
Si tout se passe bien, que vous cliquiez sur le bouton de la caméra ou que vous demandiez à l’hôte d’activer l’état de la caméra, le flux de la webcam s’affichera sur l’entité Webcam.
Si vous rencontrez un problème tel qu’un affichage orange, l’hôte ne comprenant jamais vos phrases … assurez-vous que vous avez donné au navigateur les autorisations nécessaires pour accéder au microphone et à la webcam.
Reconnaissance
La dernière partie consiste à utiliser le flux de la webcam pour détecter votre visage, puis à appeler AWS Rekognition afin de reconnaître votre visage et vos émotions.
Pour résumer le système, lorsque la webcam est activée, le script de reconnaissance crée un intervalle JavaScript qui crée une capture d’écran de la webcam dans un canevas, détecte les visages sur ce canvas et si un visage est détecté, appelle le service AWS Rekognition pour faire la reconnaissance.
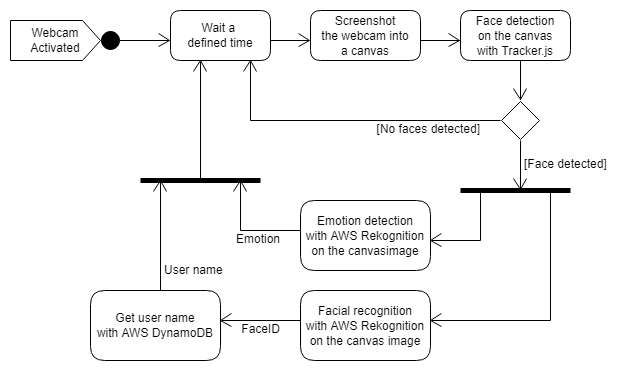
Création du système de reconnaissance
Le système de reconnaissance n’est pas compliqué à mettre en œuvre. Suivez simplement ce tutoriel pour créer le système, puis alimentez la collection de reconnaissance avec quelques images.
Gardez en mémoire l’ID de la collection et le nom de la table DynamoDB contenant les FaceID (identifiant unique de reconnaissance faciale) et les noms d’utilisateurs, pour les étapes suivantes.
Implémentation de la détection
Commencez cette étape en ajoutant le script RecognitionScript à l’entité Webcam en lui ajoutant un composant script, et configurez-le avec l’ID de collection et la table DynamoDB créée juste avant.
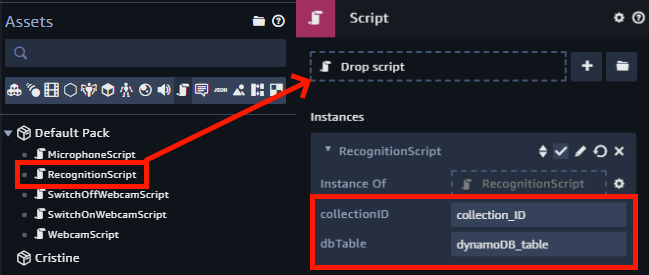
La détection faciale est effectuée par la bibliothèque Tracking.js. Le script doit donc l’inclure pour que cela fonctionne. Ouvrez le fichier RecognitionScript dans l’éditeur et ajoutez le lien au fichier tracking-min.js et face-min.js, téléchargé dans votre bucket S3 précédemment, en tant que ressources externes (sans la partie protocole HTTPS).
Avant de commencer à mettre en œuvre la détection faciale, jetez un coup d’œil au script lorsqu’il est ouvert : il contient déjà toutes les fonctions nécessaires à la reconnaissance faciale à l’aide d’AWS Rekognition.
Afin d’instancier les différents objets utilisés lors de la reconnaissance, copiez le code ci-dessous dans la fonction setup du script RecognitionScript.
rekognition = new AWS.Rekognition();
dynamodb = new AWS.DynamoDB();
tracker = new tracking.ObjectTracker('face');
tracker.setInitialScale(4);
tracker.setStepSize(2);
tracker.setEdgesDensity(0.1);
resetCurrentState(args, ctx);
Dans cette fonction, un objet appelé «tracker» est créé par Tracking.js et configuré pour détecter les visages sur les vidéos ou les images.
Vous pouvez définir l’action effectuée par le tracker lors de l’appel de la détection faciale en créant une fonction lorsque le tracker émet le message track. Si les données reçues par cette fonction ne contiennent rien, aucun visage n’est détecté. Dans le cas contraire, le tracker a détecté un visage et la reconnaissance faciale et la détection des émotions peuvent être appelées.
Une fois la fonction définie, il ne reste plus qu’à créer l’intervalle pour appeler cette détection à un intervalle de temps régulier. À chaque exécution de la fonction intervalle, une capture d’écran de la webcam est sauvegardée sur le canvas, la détection faciale est appelée puis arrêtée juste après pour éviter de surcharger l’application.
Pour effectuer toutes ces actions, copiez le code ci-dessous dans la fonction enter du script RecognitionScript (la fonction appelée lorsque le script est exécuté à partir du behaviour).
let canvas = document.getElementById("canvas");
let video = document.getElementById("video");
if(Boolean(ctx.worldData.cameraOn)){
tracker.on('track', function(event) {
//check if faces are detected
if (event.data.length === 0) {
//increment timeout to reset current user
if(currentFaceID != "" && timeout < timeoutLimit){
timeout++;
}else{
clearOutput(args, ctx);
resetCurrentState(args, ctx);
}
} else {
//facial recognition
let img = getImageFromCanvas(canvas);
imageRecognition(img, args.collectionID, args.dbTable, args, ctx);
}
});
//launch face detection every 2 seconds
interval = setInterval(function(){
drawVideoOnCanvas(video, canvas, 500, 500);
let task = tracking.track("#canvas", tracker);
task.stop();
}, frameRate);
ctx.transitions.success();
}else{
cleanup(args, ctx);
ctx.transitions.failure();
}
Pour terminer, afin de désactiver la détection si la webcam est désactivée, copiez le code suivant dans la fonction cleanup du script RecognitionScript pour tout effacer lorsque la reconnaissance s’arrête.
if(interval != null){
tracker.removeAllListeners();
clearInterval(interval);
interval = null;
}
resetCurrentState(args, ctx);
clearOutput(args, ctx);
Désormais, le système est prêt à fonctionner ! Lancez la scène sur Sumerian puis demandez à l’hôte d’activer la webcam. L’hôte devrait alors pouvoir vous détecter si votre visage est connu dans la collection de reconnaissance.
Si vous souhaitez en savoir plus sur le fonctionnement de la reconnaissance faciale et de la détection des émotions, je vous invite à lire la partie suivante.
Fonctionnement de la reconnaissance
Tous les appels de services AWS utilisent des requêtes asynchrones. Afin de synchroniser les opérations, les résultats des requêtes sont convertis en Promise (résultat d’une opération de requête asynchrone).
Détection des émotions
La détection des émotions utilise la fonction detectFaces d’AWS Rekognition prenant en paramètre l’image binaire à analyser. Le résultat est converti en Promise et contient des informations sur les visages telles que sa taille, ses émotions détectées…
function detectFace(img){
const params = {
Image: {
'Bytes': img
},
Attributes : [
"ALL"
]
};
let request = rekognition.detectFaces(params);
let promise = request.promise();
return promise;
}
Pour obtenir l’émotion principale détectée sur le visage, analysez le tableau d’émotions renvoyé par la fonction detectFace ci-dessus et renvoyez l’émotion avec le seuil de confiance le plus élevé.
let max = 0;
let maxEmotion = "unknown";
let array = promise.FaceDetails[0].Emotions;
array.forEach(array => {
if (array.Confidence > max) {
max = array.Confidence;
maxEmotion = array.Type.toLowerCase();
}
});
La principale émotion détectée est maintenant contenue dans la variable maxEmotion.
Reconnaissance faciale
La fonction de reconnaissance faciale appelle à nouveau AWS Rekognition avec la fonction searchFacesByImage. Cette fonction prend comme paramètres l’image binaire, le seuil de confiance et le nombre maximal de visages à détecter et l’ID de collection.
function facialRecognition(img, collection, threshold, maxFaces){
const params = {
CollectionId: collection,
Image: {
'Bytes': img
},
FaceMatchThreshold: threshold,
MaxFaces: maxFaces
};
let request = rekognition.searchFacesByImage(params);
let promise = request.promise();
return promise;
}
Si la Promise contient un visage détecté, vous pouvez obtenir son FaceID avec l’instruction suivante.
if (promise.FaceMatches.length > 0) {
const faceID = promise.FaceMatches[0]["Face"]["FaceId"];
}
Associer le FaceID et le nom du visage
Pour obtenir le nom associé au FaceID détecté, le script envoie une requête à une table DynamoDB contenant tous les FaceIDs et les noms associés en appelant la fonction getItem à partir d’AWS DynamoDB avec le FaceID et la table à consulter en tant que paramètres.
function getNameWithFaceID(faceID, table){
const params = {
Key: {
"RekognitionId": {
S: faceID
}
},
TableName: table
};
let request = dynamodb.getItem(params);
let promise = request.promise();
return promise;
}
Enfin, le nom reçu par la requête DynamoDB est obtenu par cette instruction.
name = promise.Item.Fullname.S;
Lorsque toutes les informations de reconnaissance sont renseignées, il suffit au script d’afficher le résultat sur l’entité 3DHTML Dialog et de faire en sorte que l’hôte prononce votre nom. Pour modifier le discours de l’hôte, il suffit de modifier le Speech de l’hôte comme ci-dessous.
function modifySpeech(text, ctx) {
let speech = ctx.entity
.getComponent("speechComponent")
.speeches[0];
speech.body = '<speak>'+ text + '</speak>';
speech.play();
speech.body = '';
}
Conclusion
Vous avez désormais ajouté tout ce dont vous avez besoin pour obtenir un hôte virtuel capable de reconnaître votre visage et vos émotions. Lancez votre scène et ouvrez la console de débogage à partir de votre navigateur pour voir s’il y a des erreurs.
Pour parler avec l’hôte, maintenez la barre d’espace ou le bouton du microphone enfoncé pendant que vous parlez.
Vous pouvez facilement améliorer le système en ajoutant d’autres fonctionnalités telles que des messages d’accueil différents en fonction de l’émotion détectée, ajouter d’autres Intent au chatbot sur Lex…
Merci d’avoir lu ce tutoriel.